Furthermore, can I run Kafka without zookeeper?
Kafka 0.9 can run without Zookeeper after all Zookeeper brokers are down. After killing all three Zookeeper nodes the Kafka cluster continues functioning. I am still able to read and write into Kafka topics.
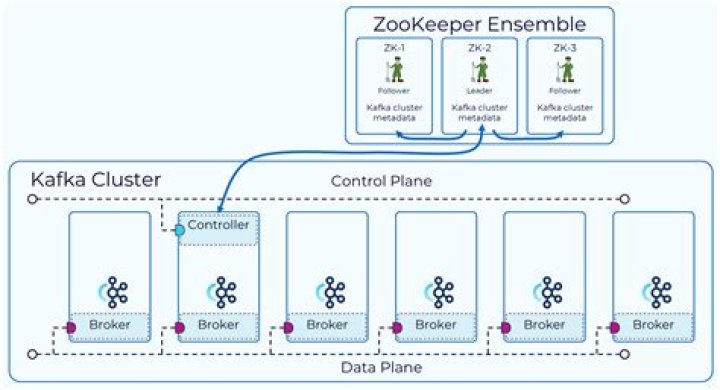
Additionally, what is the relationship between Kafka and zookeeper? Kafka Architecture: Topics, Producers and Consumers Kafka uses ZooKeeper to manage the cluster. ZooKeeper is used to coordinate the brokers/cluster topology. ZooKeeper is a consistent file system for configuration information. ZooKeeper gets used for leadership election for Broker Topic Partition Leaders.
In this regard, what happens if zookeeper goes down in Kafka?
For example, if you lost the Kafka data in ZooKeeper, the mapping of replicas to Brokers and topic configurations would be lost as well, making your Kafka cluster no longer functional and potentially resulting in total data loss.
How do I run Kafka locally?
Quickstart
- Step 1: Download the code. Download the 2.4.
- Step 2: Start the server.
- Step 3: Create a topic.
- Step 4: Send some messages.
- Step 5: Start a consumer.
- Step 6: Setting up a multi-broker cluster.
- Step 7: Use Kafka Connect to import/export data.
- Step 8: Use Kafka Streams to process data.
Does Kafka consumer need zookeeper?
With kafka 0.9+ the new Consumer API was introduced. New consumers do not need connection to Zookeeper since group balancing is provided by kafka itself.Why Kafka is faster?
Kafka relies on the filesystem for the storage and caching. The problem is disks are slower than RAM. This is because the seek-time through a disk is large compared to the time required for actually reading the data. Modern operating systems allocate most of their free memory to disk-caching.How do I run Kafka in production?
Navigate to the Apache Kafka® properties file ( /etc/kafka/server.properties ) and customize the following:- Connect to the same ZooKeeper ensemble by setting the zookeeper.connect in all nodes to the same value.
- Configure the broker IDs for each node in your cluster using one of these methods.
What ports Kafka use?
If you are running both on the same machine, you need to open both ports, of corse. kafka default ports: 9092, can be changed on server.zookeeper default ports:
- 2181 for client connections;
- 2888 for follower(other zookeeper nodes) connections;
- 3888 for inter nodes connections;
What is ZooKeeper in Kafka?
ZooKeeper is a software built by Apache which is used to maintain configuration and naming data along with providing robust and flexible synchronization in the distributed systems. It acts as a centralized service and helps to keep track of the Kafka cluster nodes status, Kafka topics, and partitions.Is Kafka open source?
Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.How many ZooKeeper nodes does Kafka have?
You need a minimum of 3 zookeepers nodes and 2 Kafka brokers to have a proper fault tolerant cluster. Recommended minimum fault tolerant cluster would be 3 Kafka brokers and 3 zookeeper nodes with replication factor = 3 on all topics.Can Kafka run on Windows?
These are the steps to install Kafka on Windows: Before you start installing Kafka, you need to install Zookeeper. Once it is download, extract the files and copy the kafka folder in C drive. Shift+Right click on the Kafka folder and open it using command prompt or powershell.Why ZooKeeper is required for Kafka?
Kafka is a distributed system and uses Zookeeper to track status of kafka cluster nodes. Zookeeper also plays a vital role for serving many other purposes, such as leader detection, configuration management, synchronization, detecting when a new node joins or leaves the cluster, etc.How do I start Kafka ZooKeeper?
Installation- Download ZooKeeper from here.
- Unzip the file.
- The zoo.
- The default listen port is 2181.
- The default data directory is /tmp/data.
- Go to the bin directory.
- Start ZooKeeper by executing the command ./zkServer.sh start .
- Stop ZooKeeper by stopping the command ./zkServer.sh stop .
